

DAU(日活)为何会骤降?给出分析思路
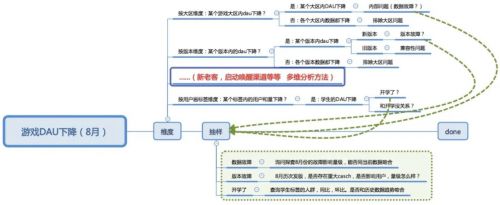
问题:假设你在一家游戏公司做数据分析,现在发现从8月份开始公司运营的某款游戏出现了DAU骤降的现象,你该如何分析这个现象?详情>>
2022-11-14算法题(力扣)--K个一组翻转链表

给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。详情>>
2022-11-08算法题(力扣)--盛水最多的容器

很容易的可以得到---->容器可以容纳水的容量=两条垂直线中最短的那条*两条线之间的距离 现在的情况是,有很多条线,让你计算两两之间能装的最多的水,其实暴力法之间就能解决这个问题,但是它的时间复杂度也达到了O(n^2) ok,那我们先试试用暴力法来解 决问...详情>>
2022-11-08nio和bio的区别为啥nio好?

2) : 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.详情>>
2022-11-08算法题(力扣)两数之和

每次遍历时使用临时变量 complement 用来保存目标值与当前值的差值,在此次遍历中查找 record ,查看是否有与 complement 一致的值,如果查找成功则返回查找值的索引值与当前变量的值 i,如果未找到,则在 record 保存该元素与索引值 i ...详情>>
2022-11-08java底层hashmap扩容怎么实现?

Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术,有些方法需要跨段,比如size()和containsValue(),它们可能...详情>>
2022-11-08用户画像系统中遇到的比较难的问题是什么?

如果我们直接将用户的标签转换为稀疏向量来存储,对于类别标签使用`one-hot`编码,但这样会出现维度爆炸的问题,向量过于稀疏,向量之间的余弦相似度计算结果基本没有意义,根本无法实现用户相似度的计算。详情>>
2022-11-07Hadoop集群安装系列------单机安装 (根据官方文档编写)

格式 hadoop jar命令 例子架包 wordcount函数 参数一:数据来源 参数二: 数据输出(统计后的结果)[root@bihai6 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /root/hadoopdata/input /root/hadoopdata/output/详情>>
2022-11-07Spark RDD在Spark中的地位和作用如何?

因为Spark是用scala语言实现的,Spark和scala能够紧密的集成,所以Spark可以完美的运用scala的解释器,使得其中的scala可以向操作本地集合对象一样轻松操作分布式数据集.详情>>
2022-11-07用户画像标签怎么去设定的

如果值的是标签的存储方式设定,我们将数据的存储模型设计成label_name,label_value,bitmap(用户)的形式,相当于每个标签和标签值下我们存储了一个Bitmap,而这个Bitmap中存储的就是用户ID.详情>>
2022-11-07















 京公网安备 11010802030320号
京公网安备 11010802030320号